Wykładzie 4 prezentujemy i omawiamy schemat oraz zawartość (dane) bardzo prostej bazy danych, na przykładzie której będą omawiane wszystkie zagadnienia związane z poleceniami języka SQL, a także część konstrukcji języka proceduralnego. W części merytorycznej omawiamy odczytwywanie danych z jednej tabeli, szczegółowo przedstawiając skłądnię klauzuli SELECT.
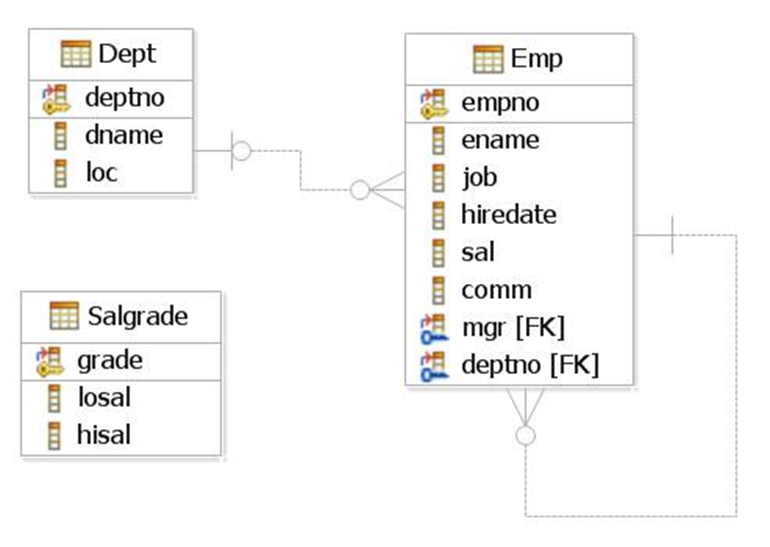
Tematem pierwszego wykładu będzie odczytywanie danych (mówimy na ogół „wykonywanie zapytań”) z jednej tabeli bazy danych. Zarówno w tym, jak też w następnych wykładach posługiwać się będziemy bardzo prostą bazą danych, o schemacie przedstawionym na rysunku poniżej.
Rysunek 4.1 Schemat tabel EMP, DEPT, SALGRADE
W trzech tabelach zapisano dane związane z działalnością pewnej, hipotetycznej firmy. Tabela EMP zawiera dane pracowników firmy, tabela DEPT dane działów (departamentów) firmy, tabela SALGRADE siatkę płac.
Deptno – numer departamentu, liczba, klucz główny tabeli.
Dname – nazwa departamentu, tekst.
Loc – lokalizacja departamentu, tekst.
Empno – numer pracownika, liczba, klucz główny tabeli.
Ename – nazwisko pracownika, tekst.
Job – stanowisko pracownika, tekst.
Hiredate – data zatrudnienia pracownika, data.
Sal – płaca miesięczna, liczba.
Comm – prowizja roczna, liczba.
Mgr – numer pracowniczy przełożonego pracownika (szefa), liczba, klucz obcy z tabeli EMP.
Deptno – numer departamentu, w którym zatrudniony jest pracownik, liczba, klucz obcy z tabeli DEPT.
Grade – grupa zaszeregowania, liczba, klucz główny tabeli.
Losal – minimalna stawka w grupie zaszeregowania.
Hisal – Maksymalna stawka w grupie zaszeregowania.
Tabele DEPT i EMP są ze sobą powiązane w układzie jeden – do – wiele, poprzez wartości kolumny Deptno pełniącej w tabeli DEPT rolę klucza głównego, w tabeli EMP rolę klucza obcego, stanowiąc wskaźnik do dokładnie jednego rekordu w tabeli DEPT. Sprawdzenie danych departamentu, w którym jest zatrudniony dany pracownik, sprowadza się do odczytania wartości z kolumny Deptno w wierszu pracownika tabeli EMP, a następnie odszukania w tabeli DEPT wiersza z taką samą wartością Deptno, jak odczytana z DEPT.
Na tabeli EMP utworzony jest również związek rekurencyjny, w którym tabela EMP pozostaje jednocześnie po stronie jeden, jak i po stronie wiele. Związek realizowany jest przez wartości kolumn Empno (klucz główny tabeli) i Mgr (klucz obcy), a jego rolą jest przypisanie (nie każdemu!) pracownikowi, jego szefa. Aby poznać szefa danego pracownika, należy w opisującym go wierszu odczytać wartość kolumny Mgr, a następnie znaleźć wiersz, dla którego wartość Empno jest równa odczytanej wcześniej wartości Mgr.
Tabele SALGRADE i EMP nie są ze sobą powiązane w układzie klucz główny – klucz obcy. Aby sprawdzić, do której grupy zaszeregowania należy dany pracownik, trzeba odczytać wartość jego płacy w kolumnie Sal tabeli EMP, a następnie w tabeli SALGRADE znaleźć wiersz, dla którego odczytana wartość Sal mieści się pomiędzy wartościami Losal i Hisal. Poniżej prezentujemy wartości zapisane w tabelach EMP, DEPT i SALGRADE.
| Empno | Ename | Job | Mgr | Hiredate | Sal | Comm | Deptno |
|---|---|---|---|---|---|---|---|
| 7369 | SMITH | CLERK | 7902 | 1980-12-17 | 800 | NULL | NULL |
| 7499 | ALLEN | SALESMAN | 7689 | 1981-02-20 | 1600 | 500 | 30 |
| 7521 | WARD | SALESMAN | 7698 | 1981-02-22 | 1250 | NULL | 20 |
| 7566 | JONES | MANAGER | 7839 | 1981-04-02 | 2975 | NULL | 20 |
| 7654 | MARTIN | ALESMAN | 7698 | 1981-09-28 | 1250 | 1400 | 30 |
| 7698 | BLAKE | MANAGER | 7839 | 1981-05-01 | 2850 | NULL | 30 |
| 7782 | CLARK | MANAGER | 7839 | 1981-06-09 | 2450 | NULL | 10 |
| 7788 | SCOTT | ANALYST | 7566 | 1982-12-09 | 3000 | NULL | 20 |
| 7839 | KING | PRESIDENT | NULL | 1981-11-17 | 5000 | NULL | 10 |
| 7844 | TURNER | SALESMAN | 7698 | 1981-09-08 | 1500 | 0 | 30 |
| 7876 | ADAMS | CLERK | 7788 | 1983-01-12 | 1100 | NULL | 20 |
| 7900 | JAMES | CLERK | 7698 | 1981-12-03 | 950 | NULL | 30 |
| 7902 | FORD | ANALYST | 7566 | 1981-12-03 | 3000 | NULL | 20 |
| 7934 | MILLER | CLERK | 7782 | 1982-01-23 | 1300 | NULL | 10 |
| Deptno | Dname | Loc |
|---|---|---|
| 10 | ACCOUNTING | NEW YORK |
| 20 | RESEARCH | DALLAS |
| 30 | SALES | CHICAGO |
| 40 | OPERATIONS | BOSTON |
| Grade | Losal | Hisal |
|---|---|---|
| 1 | 700 | 1200 |
| 2 | 1201 | 1400 |
| 3 | 1401 | 2000 |
| 4 | 2001 | 3000 |
| 5 | 3001 | 9999 |
Warto zwrócić uwagę, na niektóre wartości w powyższych tabelach. Pracownik KING, zatrudniony na stanowisku PRESIDENT (Prezes), w kolumnie Mgr ma wartość NULL, co wskazuje na fakt, że nie ma on przełożonego. Powtarzające się w kolumnie Mgr jednakowe wartości, wskazują na to, iż są pracownicy mający kilku podwładnych, co jest jednoznaczne ze stwierdzeniem, że są tacy pracownicy, którzy mają wspólnego szefa. Warte odnotowania jest także to, że tylko nieliczni pracownicy mają przyznaną prowizję. Większość w kolumnie Comm ma wartość Null, a jedna osoba 0. Można to interpretować tak, że osoby, u których występuje NULL mają prowizję niezagwarantowaną (mogą ją otrzymać, lub nie), jedna osoba ma natomiast zagwarantowany brak prowizji (pracownik Turner, mający w kolumnie Comm wartość 0). I jeszcze jedna uwaga. W tabeli DEPT zapisane są cztery rekordy opisujące cztery departament. Ale w kolumnie Deptno tabeli EMP, wartość 40 (wskazująca na departament Operations z siedzibą w Bostonie) nie występuje w żadnym rekordzie, co należy interpretować, że w tym departamencie nie jest zatrudniony żaden pracownik.
W dalszej części tego wykładu, oraz w wykładach kolejnych, będą pojawiały się instrukcje języka SQL oraz wyniki ich wykonania. Wyniki (zwłaszcza wartości liczbowe) umieszczone w treści wykładu mogą się różnić od wyników tych samych poleceń wykonywanych przez czytelnika. Nie wynika to z jakichkolwiek błędów, lecz z różnic w zawartości przykładowych tabel. Pisząc ten cykl wykładów dość często wykonywane były operacje edycji tabel, stąd niemożność zagwarantowania identyczności wyników.
Instrukcja (często używamy w tym samym znaczeniu słowa „zapytanie”) SELECT jest poleceniem odczytania danych zapisanych w bazie, bez jakiejkolwiek ingerencji w ich zawartość i strukturę. Instrukcja SELECT określa:
Instrukcja SELECT składa się z kilku części, nazywanych klauzulami, każda z nich rozpoczyna się od właściwego słowa kluczowego.
SELECT [DISTINCT] wyrażenie, ... FROM nazwa_tabeli, ... [WHERE warunek] [GROUP BY wyrażenie] [HAVING wyrażenie] [ORDER BY wyrażenie];
Klauzule SELECT i FROM muszą pojawić się w każdej strukturze instrukcji SELECT co najmniej jeden raz, pozostałe klauzule (ujęte w kwadratowe nawiasy) są używane w zależności od wymagań stawianych przed cała instrukcją.
Instrukcja SELECT, tak jak każda instrukcja SQL zamykana jest średnikiem (obligatoryjne w ORACLE, opcjonalne w MS SQL Server). Słowa kluczowe instrukcji SQL nie są case sensitive, mogą być pisane małymi lub dużymi literami.
Znaczenie poszczególnych klauzul, ich składnię oraz stawiane wobec nich wymagania będziemy omawiać sukcesywnie.
Klauzula SELECT definiuje dane, które mają zostać zwrócone (wyświetlone, wypisane) w wyniku działania całej instrukcji, oraz sposób ich prezentacji. Ogólnie rzecz ujmując, są nimi wyrażenia, którymi mogą być nazwy kolumn, wyrażenia odwołujące się do nazw kolumn, stałe, niezwiązane z danymi zapisanymi w bazie, a także wyrażenia zawierające wszystkie te elementy. Wyrażenia oddzielane są przecinkami.
Odwołanie do nazwy kolumny w wyrażeniu ma następującą postać:
Nazwa_tabeli.Nazwa_kolumny
Jeżeli nazwy kolumn w instrukcji SELECT są jednoznaczne, nazwę tabeli poprzedzającą nazwę kolumny można opuścić. Jednoznaczność oznacza tu, że nazwa kolumny występująca w klauzuli SELECT występuje tylko w jednej z tabel, z których instrukcja odczytuje dane.
W MS SQL Server w klauzuli SELECT może pojawić się słowo TOP, określające liczbę, lub procent rekordów, które mają zostać odczytane
SELECT TOP n [PERCENT]
Klauzula FROM definiuje źródła, z których dane będą odczytywane. Mogą nimi być tabele, widoki i inne instrukcje SELECT. Nazwy tabel, widoków i instrukcji SELECT (ujętych w okrągłe nawiasy) oddzielane są przecinkami. W tej części wykładu ograniczamy się tylko do odczytywania danych z tabel (odczyt danych z widoku, z punktu widzenia konstrukcji zapytania, niczym nie różni się od odczytu z tabeli).
Wypisz nazwiska (Empno), zarobki (Sal) i stanowiska (Job) wszystkich pracowników, zapisane w tabeli EMP.
SELECT Ename, Sal, Job FROM EMP;
Aby wypisać dane z wszystkich kolumn tabeli, można użyć skróconej formy zapytania:
SELECT * FROM EMP;
gdzie symbol * zastępuje wymienianie nazw wszystkich kolumn.
Standard języka SQL dopuszcza także jeszcze bardziej skrócony zapis:
TABLE EMP;
Ta forma działa w ORACLE, nie została zaimplementowana w MS SQL.
Wynikiem działania tej instrukcji, dla przedstawionych powyżej tabel, jest zestaw wszystkich wierszy danych odczytanych z tabeli EMP z bazy danych.
W powyższym przykładzie odwoływaliśmy się do jednej tabeli EMP i odczytywaliśmy dane w takiej postaci, w jakiej zostały w niej zapisane. Ale, jak wspomniano wyżej, wynikiem zapytania mogą być wyrażenia, zawierające (lub nie) odwołania do kolumn tabel.
Wypisz w jednej kolumnie wynikowej wszystkie nazwiska (Ename) z tabeli EMP, poprzedzając je tekstem „Nazwisko pracownika: ” a następnie uzupełnić informacją o zarobkach (Sal).
SELECT ’Nazwisko pracownika: ’ + Ename FROM EMP;
W przypadku łączenia wartości tekstowej z numeryczną musimy dokonać konwersji wartości numerycznej na tekstową (ORACLE wykona to niejawnie):
SELECT Ename + ’ ’ + CAST(Sal as VARCHAR) FROM EMP;
Należy zwrócić uwagę na konieczność ujmowania wszystkich wyrażeń tekstowych (w powyższym przykładzie dotyczy to spacji) w pojedyncze cudzysłowy.
Funkcja konwertująca CAST(wyrażenie AS Typ_danych[n]) implementowana jest (zgodnie ze standardem) zarówno w MS SQL jak i w ORACLE. Zwraca wyrażenie przekształcone do Typu_danych. W MS SQL opcjonalna liczba n określa liczbę znaków zwracanych przez funkcję (domyślnie 30).
MS SQL implementuje drugą funkcję konwertującą, trzyargumentową funkcję CONVERT o następującej składni:
CONVERT(Typ_danych, Wyrażenie, [Format])
gdzie opcjonalny argument Format jest liczbą całkowitą określającą formatowanie dat i czasu zwracanych przez funkcję. Na przykład wartość 112 określa datę formatowaną wg standardu ISO: yyyymmdd. Zainteresowanych dalszymi szczegółami odsyłamy do dokumentacji.
ORACLE w celu konwersji typów używa jeszcze kilku innych funkcji, które nie będą tutaj omawiane (np. funkcja TO_CHAR(wyrażenie) zwracająca wyrażenie przekształcone do typu Varchar2).
Wyrażeniom zwracanym w klauzuli SELECT mogą zostać nadane nazwy, czyli aliasy. Alias może występować w postaci prostego identyfikatora, czyli napisu złożonego z liter, cyfr i znaków podkreślenia. Identyfikator ograniczony różni się od identyfikatora prostego tym, że MOŻE zawierać spacje i MUSI być ujęty w podwójne cudzysłowy. Alias może zostać poprzedzony słowem AS przewidzianym przez standard języka, dopuszczalnym, ale niewymaganym w większości implementacji.
Oczywiście użycie aliasu w zastosowaniu do kolumny tabeli nie zmienia rzeczywistej jej nazwy i ogranicza się wyłącznie do tej instrukcji, w której został on użyty.
Wynikową kolumnę, zwracaną przez polecenie z przykładu 4.2, nazwij „Informacje o pracowniku” i dodaj drugą kolumnę, zwracającą wartości z kolumny Job, zatytułowaną „Zawód”.
SELECT Ename + ’ ’ + CAST(Sal as VARCHAR) As “Informacje o pracowniku”, Job Zawód FROM EMP;
W powyższym przykładzie użyty został alias ograniczony dla nazwania pierwszej kolumny wynikowej, i alias prosty dla drugiej kolumny. Proszę zwrócić uwagę, że w pierwszym przypadku użyte zostało słowo AS poprzedzające alias, w drugim przypadku opuszczone. Jak widać, obie formy są akceptowane.
Użycie aliasów kolumn, na ogół podyktowane jest dążeniem do uzyskania lepszej czytelności zwracanych danych, pozwalając nazwać w sposób znaczący kolumny wynikowe.
Jednym z Postulatów Codd’a, czyli aksjomatów relacyjnego modelu danych, jest konieczność wprowadzenia trzeciej wartości logicznej NULL, obok TRUE i FALSE, oznaczającą brak informacji. NULL nie jest zerem, nie jest też „pustym stringiem”, czyli napisem o zerowej długości. Mówiąc obrazowo, NULL oznacza albo TRUE, albo FALSE, ale z braku danych nie jesteśmy w stanie jednoznacznie określić, co.
Każda operacja porównania, arytmetyczna, konkatenacja, w której jednym z operandów jest NULL daje w wyniku NULL.
5 * NULL = NULL
‘Ala’ + NULL = NULL
Także wynik porównania NULL = NULL ma wartość logiczną NULL (!)
Natomiast operacje logiczne z udziałem NULL dają w wyniku NULL, poza
NULL OR TRUE = TRUE
NULL AND FALSE = FALSE
Szczególnie trzeba podkreślić, że NOT NULL = NULL (!)
Te właściwości NULL wymusiły konieczność wprowadzenia rozwiązań pozwalających zamienić wartość NULL na dowolną wartość znaczącą, oraz testujących, czy wyrażenie ma wartość NULL, czy znaczącą.
ISNULL(wyrażenie, zamienić_na) w MS SQL Serwer
NVL(wyrażenie, zamienić_na) w ORACLE
NZ(wyrażenie, zamienić_na) w MS Access
Funkcje te zwracają wartość pierwszego argumentu, jeśli nie jest on NULL, lub drugi argument.
UWAGA: oba argumenty muszą być tych samych typów (w przypadku niezgodności ORACLE skonwertuje je niejawnie, w MS SQL Serwer trzeba użyć funkcji konwertujących).
Wypisz wszystkie (w składni MS SQL) nazwiska pracowników (Ename) z tabeli EMP, oraz roczne dochody, zakładając, że są one równe dwunastu pensjom (Sal), powiększonym o jedną prowizję (Comm).
SELECT Ename As Nazwisko, 12*sal + ISNULL(Comm, 0) As “Roczne dochody” FROM EMP;
Konieczność użycia funkcji ISNULL wynika z faktu, że dla znacznej części pracowników prowizja Comm nie jest określona (ma wartość NULL), zatem wykonanie operacji 12*sal + Comm dałoby dla ich wierszy wynik NULL, co oczywiście jest niezgodne z prawdą.
W celu sprawdzenia, czy wyrażenie ma wartość NULL, czy znaczącą, wprowadzono operatory testujące IS [NOT] NULL. Użycie ich ma następującą składnię:
Wyrażenie IS NULL przyjmuje wartość TRUE, jeśli wyrażenie ma wartość NULL.
Wyrażenie IS NOT NULL przyjmuje wartość TRUE, jeśli wyrażenie ma wartość znaczącą.
Przykład ilustrujący użycie tych operatorów zostanie przedstawiony w dalszej części wykładu.
Powtarzające się wiersze nie są automatycznie eliminowane z wyników zapytania. Słowo DISTINCT użyte w składni instrukcji po słowie SELECT oznacza eliminację powtarzających się wierszy. Wymaga to posortowania wierszy wynikowych, aby można było wyznaczyć grupy powtarzających się wierszy.
Wypisz, bez powtórzeń, stanowiska pracowników (Job) z tabeli EMP.
SELECT DISTINCT Job FROM EMP;
Wiersze tabel przechowywane są w bazie danych na ogół w porządku wynikającym z kolejności ich dopisywania do bazy. Jeżeli nie zostanie zastosowany mechanizm ich sortowania, są także w takiej kolejności zwracane w wyniku instrukcji SELECT. Jest rzeczą oczywistą, że taki układ wyniku rzadko jest satysfakcjonujący. W celu umożliwienia sortowania wierszy wynikowych, wprowadza się klauzulę sortującą ORDER BY definiującą, według której kolumny wynikowej dane mają zostać posortowane, oraz jaki ma być porządek sortowania – rosnący (ASCENDING, ASC), czy malejący (DESCENDING, DESC).
Składnia instrukcji SELECT zawierająca klauzulę sortowania wygląda następująco:
SELECT [DISTINCT] wyrażenie1 [[AS] alias], wyrażenie2 [[AS] alias],... FROM nazwa_tabeli [ORDER BY wyrażenie1 [ASC|DESC],...];
Klauzula ORDER BY jest jedyną klauzulą w składni instrukcji SELECT, która może się pojawić tylko jeden raz, zawsze jako ostatnia klauzula w całej instrukcji. Klauzula ORDER BY może odwoływać się do wyrażeń zdefiniowanych w klauzuli SELECT, do ich aliasów, a także do numerów określających kolejność występowania wyrażeń w klauzuli SELECT. Sortowanie może odbywać się według kilku wyrażeń przywołanych w klauzuli ORDER BY. W takim przypadku hierarchia sortowania jest określana według kolejności pojawiania się wyrażeń w klauzuli ORDER BY. Na liście ORDER BY może pojawić się wyrażenie, alias wyrażenia nadany w klauzuli SELECT, albo kolejny numer wyrażenia na liście SELECT.
Wypisz nazwiska (Ename), stanowiska (Job) i roczny dochód (Sal) pracowników z tabeli EMP. Wynikowe wiersze proszę posortować rosnąco według stanowisk, malejąco według płac w obrębie każdego stanowiska.
W rozwiązaniu powyższego przykładu opuszczony został domyślny wyróżnik sortowania ASC po kolumnie Job. Jak widać, można odwoływać się w klauzuli ORDER BY do wprowadzonych w klauzuli SELECT aliasów...
SELECT Ename As Nazwisko, ,12* Sal + ISNULL(Comm, 0) As “Płaca roczna” ,Job As Stanowisko FROM EMP ORDER BY Job, “Płaca roczna” DESC;
…albo kolejności kolumn w klauzuli SELECT:
SELECT Ename As Nazwisko, ,12* Sal + ISNULL(Comm, 0) As “Płaca roczna” ,Job As Stanowisko FROM EMP ORDER BY 3, 2 DESC;
Sortowanie wierszy może zostać rozszerzone o ich numerowanie, wypisywane w
dodatkowe kolumnie. Służą do tego funkcje ROWNUM w ORACLE oraz ROW_NUMBER w MS
SQL. W ORACLE funkcja ROWNUMBER jest uruchamiana, jako wyrażenie w klauzuli
SELECT. Rozwiązanie przyjęte w MS SQL jest nieco bardziej skomplikowane, ale za
to znacznie bardziej elastyczne. Pokażemy to na przykładzie. Na początku wersja
uproszczona.
Przykład 4.7.
Wypisz nazwiska (Ename), stanowiska (Job) i roczny dochód (Sal) pracowników z tabeli EMP. Wynikowe wiersze proszę posortować i ponumerować rosnąco według pensji miesięcznej.
SELECT Ename ,12*sal + ISNULL(Comm, 0) As roczna ,Job ,ROW_NUMBER() Over(ORDER BY Sal) FROM emp;
Proszę zwrócić uwagę, na zmianę ulokowania klauzuli ORDER BY. Powyższa konstrukcja może zostać rozszerzona, poprzez wskazanie kolumny, według której jednakowych wartości zostaną utworzone grupy rekordów, w obrębie, których będzie wykonywane niezależne numerowanie.
Wypisz nazwiska (Ename), stanowiska (Job) i roczny dochód (Sal) pracowników z tabeli EMP. Wynikowe wiersze proszę posortować i ponumerować rosnąco według pensji miesięcznej, niezależnie dla każdego stanowiska (Job).
SELECT Ename ,12*sal + ISNULL(comm, 0) As roczna ,Job ,ROW_NUMBER() Over(PARTITION BY Job ORDER BY Sal) FROM emp;
W wyniku tej instrukcji otrzymamy wiersze posortowane według stanowisk Job, a w obrębie każdej grupy rekordów (utworzonej dla jednakowych wartości Job), zostaną one posortowane i ponumerowane malejąco, zgodnie z wartościami pensji miesięcznych. Należy zwrócić uwagę na fakt, że w składni OVER(PARTITION BY … ORDER BY …) możemy tylko odwoływać się do nazw kolumn w tabeli (odwołania do aliasów lub kolejności wystąpień w klauzuli SELECT są nieakceptowane.
Jeszcze jeden, a właściwie trzy przykłady w jednym.
Utwórz polecenie odczytujące wartość stałą (dowolną) z tabel EMP, DEPT I SALGRADE
SELECT 1 FROM EMP;
SELECT ‘Ala ma kota’ FROM DEPT;
SELECT Getdate() FROM EMP;
Wynikiem tych poleceń będzie w każdym przypadku tyle rekordów, ile zawiera tabela. Każdy rekord będzie zawierał wartość podaną w klauzuli SELECT.Te wyniki są zupełnie niezależne od wartości zapisanych w tabelach. Zależą wyłącznie od liczby rekordów w tabelach. Warto będzie przypomnieć sobie ten przykład, gdy będziemy liczyli rekordy w tabeli.
Dotychczas, we wszystkich przykładach milcząco zakładaliśmy, że w wyniku interesują nas wszystkie wiersze zapisane w tabeli. Oczywistym jest, że język SQL dysponuje narzędziami, pozwalającymi zdefiniować, które wiersze maja zostać odczytane, a pominąć pozostałe. Służy do tego klauzula opcjonalna WHERE, trzecia w kolejności po klauzulach SELECT i FROM.
Klauzula WHERE pozwala zdefiniować warunek logiczny, który może zostać zinterpretowany, jako TRUE, FALSE lub NULL. Wiersze w tabeli, dla których ten warunek przyjmie wartość TRUE zostaną odczytane i dostarczone do zbioru wierszy wynikowych poleceni, natomiast wiersze, dla których ten warunek przyjmie wartość FALSE lub NULL, nie znajdą się w wyniku. Zwracamy szczególną uwagę czytelnika, że te wiersze, dla których warunek z klauzuli przyjmie wartość NULL nie wejdą do wyniku(!). Ta właściwość nie jest oczywista dla osób rozpoczynających pracę z językiem SQL.
Warunek logiczny w klauzuli WHERE konstruowany jest, jako zbiór wyrażeń, które mogą przyjmować wartość logiczną, połączonych operatorami logicznymi i operatorem porównań tak, aby całość można było interpretować, jako T, F, N.
Wypisz nazwiska (Ename) pracowników zarabiających (Sal) powyżej 2000.
SELECT Ename, FROM EMP WHERE Sal > 2000;
Warunek WHERE może też być koniunkcją (AND), alternatywą
(OR) bądź negacją (NOT) innych warunków logicznych, przy zachowaniu hierarchii
operatorów: NOT, AND, OR.
Hierarchia może zostać zmieniona przy użyciu nawiasów.
Wypisz numery (Empno), Nazwiska (Ename), zarobki (Sal), i stanowiska (Job) pracowników pracujących na stanowisku 'CLERK', których zarobki są większe lub równe 1100.
SELECT Empno, Ename, Job, Sal FROM EMP WHERE Sal >= 1100 AND Job = 'CLERK';
Należy zwrócić uwagę na kilka szczególnych przypadków użycia wyrażeń w klauzuli WHERE:
... WHERE 1 = 1 lub ... WHERE ‘Ala’ = ‘Ala’
W powyższych przykładach zwrócone zostaną wszystkie rekordy z tabeli, gdyż porównanie jednakowej wartości liczbowej, lub tekstowej, zawsze ma wartość logiczną TRUE. Z tego samego powodu porównanie:
... WHERE 1 = 2 lub ... WHERE ‘Ala’ = ‘Ola’
zawsze daje wartość FALSE.
W szczególności
... WHERE wyrażenie1 = wyrażenie1
Zwrócone zostaną te wszystkie rekordy, dla których wyrażenie1 (np. wartość w kolumna1) nie jest Null.
... WHERE wyrażenie1 = wyrażenie1 OR wyrażenie1 IS NULL
Zwrócone zostaną wszystkie rekordy (cała relacja).
Przy konstruowaniu wyrażeń wewnątrz klauzul SELECT i WHERE (a także w nieomawianych dotychczas klauzulach GROUP BY i HAVING) mogą zostać użyte operatory. Poniżej przedstawiamy przegląd operatorów dopuszczalnych w SQL, z uwzględnieniem różnic pomiędzy dialektami MS SQL i ORACLE.
+ suma
- różnica
* iloczyn
/ iloraz
|| ORACLE
+ MS SQL
Wypisz w jednej kolumnie Nazwiska (Ename) i stanowiska (Job) pracowników, łącząc je dodatkowym tekstem.
Ms SQL
SELECT 'Osoba ' + ENAME + ' pracuje na stanowisku ' + JOB FROM EMP;
ORACLE
SELECT OSOBA ' || ENAME || ' pracuje na stanowisku ' || JOB FROM EMP;
= równy
<> nierówny (różny)
<> nierówny (różny)
< mniejszy
<= mniejszy
> większy niż lub równy
>= większy niż lub równy
W ORACLE i MS SQL argumenty operatorów porównań muszą być wyrażeniami, w Standardzie mogą być listami wyrażeń, (ale o tej samej liczbie elementów) – wówczas porównania odbywają się po składowych.
x IS [NOT] NULL
NOT negacja
AND koniunkcja
OR alternatywa
x [NOT] IN (x1,....)
Np.
Kolor IN ('Czarny', 'Biały', 'Czerwony')
Grupa IN (201, 202, 203)
x [NOT] BETWEEN z AND y
W ORACLE x, y, z muszą być wyrażeniami liczbowymi lub typu daty, w Standardzie mogą być listami wyrażeń tej samej długości – porównania odbywają się po składowych. Przedział określony wartościami x i z jest przedziałem domkniętym, zatem wartości x i y należą do przedziału.
Np. płaca z przedziału 1000 i 2000
SAL BETWEEN 1000 AND 2000
x [NOT] LIKE y
gdzie y to:
Na przykład użycie w klauzuli
WHERE ENAME = 'Kowalski’
zwraca wszystkie rekordy, dla których w polu ENAME znajduje się napis Kowalski.
Ale użycie konstrukcji:
ENAME LIKE 'Kowal%'
zwróci poza Kowalskimi także Kowalewskich, Kowalów itd.
Z kolei użycie
ENAME LIKE 'Kowalsk_’
zwróci poza Kowalskimi także panią Kowalską („…ja jestem Roch Kowalski, a to jest pani Kowalska…”).
Częstym błędem, popełnianym przez początkujących „eksplorerów” języka SQL, jest próba użycia operatora LIKE w połączeniu z wyrażeniem typu nietekstowego. Oczywiście, taka próba skazana jest na niepowodzenie.