SQL (= Structured Query Language) is the dedicated language which allows accessing and processing data stored in a relational database. It operates on the level of objects of the relational model, i.e. tables and views. SQL is a standard adopted by ANSI and ISO.
SQL may be also used in programs written in conventional programming languages. There are interfaces to use SQL in C, C++, Java, Visual Basic and many others. Two of the further lectures describe SQL interfaces for Visual Basic and Java.
There are also 4GL (= 4th Generation Language) programming environments where client applications are automatically generated by tools (like Oracle Forms and MS Access) and it is not necessary to write traditional programs.
Lecture 9 describes fundamental kinds of SQL statements. You have to know them, if you want to create a database application in any environment. In particular, SQL is used in MS Access.
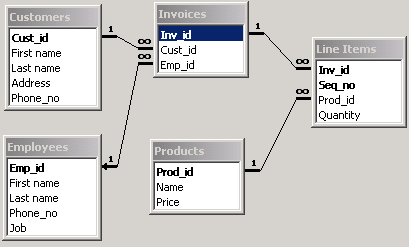
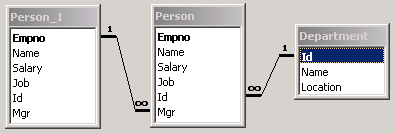
In this lecture we will describe the fundamental statements of SQL. As the running example we will use the database Invoices which has the following schema.
Note the type of the relationship between Invoices and Employees. It is defined to be the outer join. Therefore, whenever we join these tables, we want to see pairs of matched invoices and employees as well as the invoices which are not related to any employee.
We will execute the queries in the MS Access environment. Lecture 2 has presented the way to create queries in the design view by means of the query grid. Queries have one more view. It is the SQL view. The simplest way to obtain an SQL statement is to create a view in the design view and then switch to the SQL view. However, this works in MS Access only. Therefore, during this lecture we will use the direct method. We will simply write SQL code.
We encourage you to test the presented statements. In order to do it, create a database Invoices with the schema shown above and enter sample data.
The SELECT statement retrieves data from the database. It consists of parts called clauses:
FROM
WHERE
SELECT
SELECT column_name,...
|
The phrase SELECT column_name,... denotes a list of columns
separated with commas. The WHERE clause is optional, thus an SQL statement may also look
as follows:
SELECT column_name,...
|
We start from examples without the WHERE clause. Here is the first query.
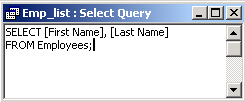
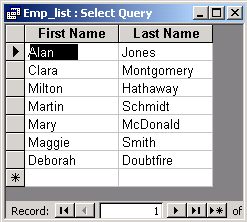
| Display first name and last name of each employee. |
We define the query as the following SQL statement:
SELECT [First name], [Last name]
|
In laboratory classes we will use MS Access to write and test queries. We can create an SQL statement as follows.
Here is the picture of what it looks like in MS Access:
and the result of the query:
The next query is even simpler.
| Display the whole content of the table Employees. |
As you probably expected, "all" is denoted by the asterisk:
SELECT *
|
The result will be as follows:
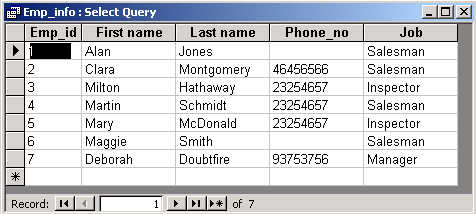
Now it is your turn. Write the query to answer the following question:
| Display the first name, the last name and the phone number of each employee. |
The result of a query may be formatted freely. Instead of names of columns, you can use
any expressions. Let us assume that we want to see text information on employees.
In order to concatenate strings, we use symbol '&'. Keyword AS
allows renaming the label of an output column.
SELECT [First name] & " " & [Last name] &
" is employed as " & [Job] AS [Emp info]
|
Remember that brackets are used to isolate identifiers which contain special characters, e.g. spaces.
Here is the result of this query:
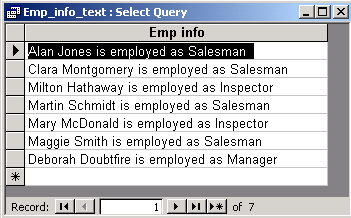
Again your turn. Write the query that answers the following question:
| Display the full information on customers in the text form. |
Further examples will have the WHERE clause. The next query is:
| Display all managers. |
The managers satisfy the condition Job = "Manager".
We put it into the WHERE clause:
SELECT [First name], [Last name]
|
The result is:
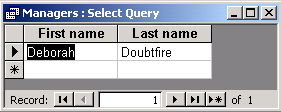
Here is the next task for you:
| Display all customers with the first name "Ian". |
Let us consider the following problem:
| Display phone numbers of employees without duplicates. |
The solution uses the keyword DISTINCT which eliminates the duplicates
from the resulting set of rows.
SELECT DISTINCT Phone_no
|
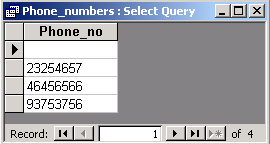
As a result we have four rows. One of them holds NULL
which
denotes the lack of value.
ORDER BY is an optional clause of SELECT statement which is used to order
rows in the result. This clause always occurs as the last one. It has the following form:
ORDER BY column_name specifier,...
|
The specifier is either ASC (ascending)
or DESC (descending). The specifier is optional. If you omit it,
the ascending order is assumed.
| Display employees in reverse order of their second names. |
We will use the specifier DESC:
SELECT [First Name], [Last Name]
|
The result:
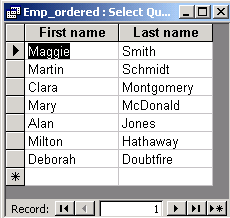
We would get the ascending order if we wrote ASC instead of
DESC.
Here is another exercise for you.
| Display the information on customers ordered by second names. If they are equal, use first names. If both the first and the second names are equal, use the identifiers. |
In order to test whether a value is NULL, use predicate
IS NULL. Predicate IS NOT NULL is its negation.
| Display employees who have no phone number. |
We use predicate IS NULL.
SELECT [First Name], [Last Name]
|
Predicate BETWEEN is true if the given value belongs to the
specified range (the ends of the range are included).
Predicate NOT BETWEEN is its negation.
| Display employees with identifiers from the range between 2 and 4. |
SELECT [First Name], [Last Name]
|
Predicate BETWEEN is equivalent
to the conjunction of two inequalities, e.g.
Emp_id <= 2 AND Emp_id >= 4.
|
Which form would you prefer?
Predicate LIKE is true if the given value matches the specified
pattern. Predicate NOT LIKE is its negation.
We remind you that the asterisk in the pattern matches any text (even empty),
the question mark matches any character and the hash matches any digit.
| Display employees with last names that begin with "K". |
SELECT [First Name], [Last Name]
|
Here is another task for you.
| Display customers with last names that begin with "K" and end with "s". |
Predicate IN is true, if the given value belongs to the
specified set. Predicate NOT IN is its negation.
| Display employees with managerial jobs. |
SELECT [First Name], [Last Name]
|
Predicate IN is equivalent
to the disjunction of equalities, e.g.
Job = "Manager" OR Job = "Director" OR Job = "CEO"
|
Which form would you prefer?
Atomic predicates can be combined by logical connectives:
the disjunction (OR), the conjunction (AND)
and the negation (NOT).
| Display employees who have a phone number and second names that end with "K". |
It is the conjunction of simple predicates.
SELECT [First Name], [Last Name]
|
Please write a query which answers the following question.
| Display customers who have no phone number or no address. |
The INSERT statement is used to add rows to a table. It consists of two
clauses INTO and VALUES.
INSERT INTO table_name(column_name,...)
|
A column which is not listed in clause INTO is set to NULL
in the new row, unless it is of type Autonumber or
default values have
been set for it.
| Add a new employee to table Employees. |
INSERT INTO Employees([First Name], [Second name], Job)
|
Two columns of the table Employees are absent in this statement.
Emp_id will be automatically set to the next sequence number, while
Phone_no will be NULL.
The DELETE statement is used to delete rows from a table.
It consists of two clauses FROM and WHERE.
The latter clause is optional.
DELETE FROM table_name
|
The rows which satisfy the condition will be deleted
from table table_name. If the clause WHERE is missing,
all rows from the table are deleted.
| From the table Employees delete all rows on persons employed as managers. |
DELETE FROM Employees
|
The UPDATE statement is used to modify rows of a table.
It consists of three clauses UPDATE,
SET and WHERE. Only WHERE
is optional.
UPDATE table_name
|
The rows of table table_name which satisfy the condition
will be updated. The modification will consist in performing assignments
column_name= expression for each column
which occurs on the left side of the equality sign in clause SET.
| In the table Employees change the phone number "4565666" to "1265666". |
UPDATE Employees
|
Here is an exercise for you.
In
table Customers change NULL phone no. values to text "NONE".
|
You can combine the results of several SELECT statements provided they return the same number of columns which have the same types.
SELECT_statement UNION SELECT_statement
|
This form of a query cannot be created by means of the query grid. You have to use the SQL view. To reach the SQL view, just open the query in the design view and them switch to the SQL view or select menu item "Query -> SQL Specific -> UNION".
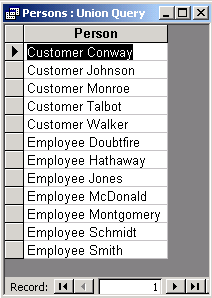
| Display last names of employees and customers. Precede each name of an employee with the word "Employee" and each name of a customer with the word "Customer". |
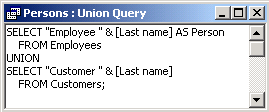
The result:
Among items in menu "Query -> SQL Specific" there are two more.
CREATE TABLE),
a change of the schema of a table (ALTER TABLE),
the deletion of a table (DROP TABLE). They will be presented during
the sequel lecture Database systems.
Now we will discuss more complex SELECT statements with joins. Here is a typical question which can be solved with a join.
| Display customers and the identifiers of their invoices. |
We will use a method which can be used in many other cases. We will design the query by means of the query grid in the design view. Then we switch to the SQL view to obtain the text of the desired SQL statement.
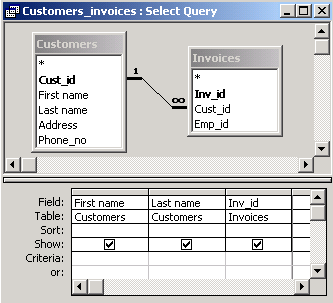
The SQL view shows the corresponding SQL statement.
SELECT Customers.[First name], Customers.[Last name], Invoices.Inv_id
|
It is an INNER JOIN of tables Customers and
Invoices. The join conditions uses the connection primary key-foreign key.
Here is the general syntax of the inner join of two tables which can be used
in clause FROM.
Table1 INNER JOIN Table2 ON
Table1.column1 =
Table2.column2
|
The names of columns are prefixed with the names of tables. In the case of column Cust_id it is unavoidable because otherwise the query engine would have no means to recognize what table the column came from. This name of the column occurs in both tables.
The inner join can be specified without the operator INNER JOIN. Simply, put
the join condition into the WHERE clause of the query.
FROM Table1, Table2
|
Therefore, the previous query can also be formulated as follows:
SELECT Customers.[First name], Customers.[Last name], Invoices.Inv_id
|
It is time for another task for you.
| For each product display its name, prices and the identifier of invoices where the product occurs. Show also the ordered quantities. |
Let us consider the following query.
| Display employees and the orders they have collected. |
As before, we will use the query grid:
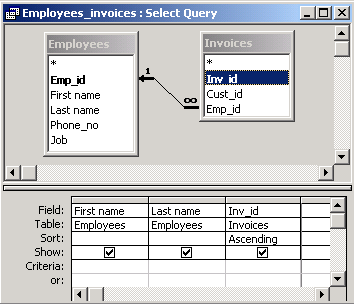
The join between employees and invoices is outer, i.e. invoices which are not assigned to any employee are also shown. In rows which represent such invoices first name and second name are empty.
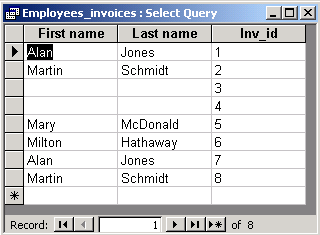
The SQL view shows the corresponding SQL statement.
SELECT Employees.[First name], Employees.[Last name], Invoices.Inv_id |
It is a RIGHT OUTER JOIN of tables Employees and
Invoices. Here is the general syntax of the outer join of two
tables which can be used in the clause FROM.
Table1 RIGHT OUTER JOIN Table2 ON
Table1.column1 =
Table2.column2
|
Such an expression means that the query engine is to display all rows of
Table2 (the one that is on the right side) regardless
of whether there are matching rows of Table1.
If we use LEFT instead of LEFT, all rows of
Table1 (the one that is on the left side)
will be shown.
The operator DISTINCTROW is not an element of the standard SQL.
The operator DISTINCT has been used in one of the examples at the beginning
of this lecture. It orders the query engine to eliminate the duplicates.
We will present the differences between the two operators using three versions of the same example query (the inner join of Customers and Invoices):
DISTINCT nor DISTINCTROW,
DISTINCTROW and
DISTINCT.
The result of the following query contains duplicates:
SELECT Customers.[First name], Customers.[Last name]
|
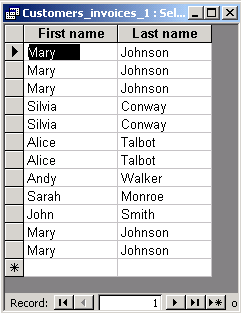
The result of the following query contains one pair of duplicates:
SELECT DISTINCTROW Customers.[First name], Customers.[Last name]
|
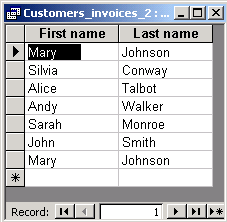
If you use DISTINCTROW, the query engine will create a separate output
row for each row of table Customers. In this table there are two persons
called Mary Johnson. They have different identifiers and each of them has at least
one invoice. Therefore, we get a separate output row for each input row with Mary Johnson.
The result of the following query contains no duplicates:
SELECT DISTINCT Customers.[First name], Customers.[Last name]
|
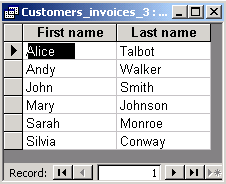
If you use DISTINCT, the query engine will create a separate output
row for each different value taken from table Customers. Thus, the records
with Mary Johnson are collapsed. Of course, if we added column Cust_id
(the primary key), both DISTINCT and DISTINCTROW would yield
the same result.
There is one more specific kind of join, called the self-join. It is the join of a table with itself. Its join condition is usually based on the pair primary key-foreign key of a recursive relationship.
Let us consider the parenthood relationship. We will represent it in the table Persons. Each of its rows contains the information on the mother and the father. It is stored in two foreign keys: Mother and Father which reference the primary key of the same table. In order to define such recursive relationships, you have to show this table three times on the relationship diagram of MS Access. This is different from MS Visio where we show the same table only once.
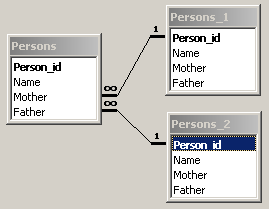
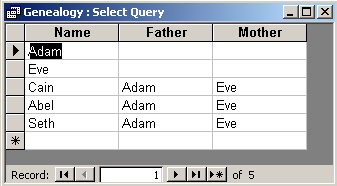
We want to see the table which shows the name of each person together with the names of his/her father and mother.
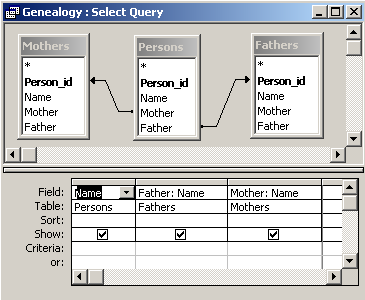
In order to define such a query, we use three virtual copies of the table Persons:
We introduce two latter aliases in the clause FROM of the query.
One copy need no alias, because it is used under the name of the table.
SELECT Persons.Name, Fathers.Name AS Father, Mothers.Name AS Mother
|
This query can be constructed in the query grid as well. We simply add the same table three times. We have to add the relationships because they are not created automatically. Make the query an outer join, because we want to see persons whose parents are not stored in the database. If we use the inner join, we will see only those whose mother and father are both inserted into the database.
Here is a task for you.
| List persons and for each person display the names of his/her grandfathers. |
Aggregate functions play a special role in queries. Here are their semantics:
COUNT()
MAX()
MIN()
SUM()
AVG()
SELECT Count(Prod_id), Min(Price), Max(Price), Sum(Price), Avg(Price) |
Produces one row with the number of rows in the table Products, the minimum price, the maximum price, the sum of the prices and the average price.
| Please type this query into MS Access in the SQL view, and then switch to the design view to see what the query looks like in the query grid. |
The clause GROUP BY partitions rows into groups
and calculates
totals inside these groups. Let us consider the following query:
| Display the number of invoices of every customer. |
As before we will use the query grid. We will enrich it by adding the row with totals. To do it, we select the menu item "View -> Totals".
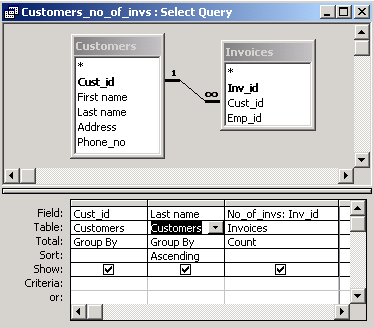
We choose "Group by" for columns Cust_id and Last Name and the aggregate function ("Count") for column Inv_id. We precede the call to this function with the name for this column, i.e. No_of_invs. As a result we get the number of invoices of every customer.
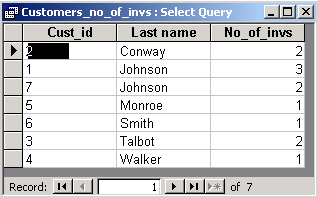
The SQL view shows the corresponding SQL statement.
SELECT Customers.Cust_id, Customers.[Last name], Count(Invoices.Inv_id) AS No_of_invs |
The clause GROUP BY appeared just below the clause
FROM. It told the database engine
to partition the rows as the results of the
INNER JOIN. The clause
SELECT specifies the values which must be displayed
for all the groups defined by the clause GROUP BY. The clause
SELECT may contain columns which are listed by the clause
GROUP BY as well as the calls to aggregate functions on the
columns not listed by the clause GROUP BY.
GROUP BY column, .... |
Here is a task for you:
| For every product display its name, price, the number of invoices with it and the total value of it on all invoices. |
Consider the next query.
| For every employee display the number of invoices signed by him/her. |
This time we will use the outer join of the tables Invoices and Employees. We will also display the employees who signed no invoices, but we will not show the invoices signed by no employees. We design this query in the query grid.
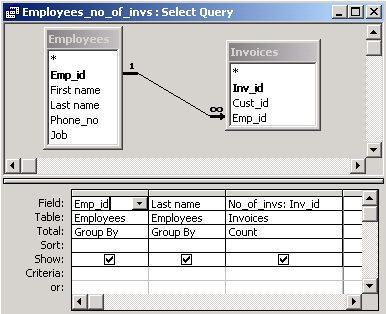
In the result table there are rows which describe employees who signed no invoices.
For such employees the column No_of_invs is equal to zero.
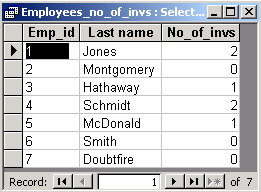
The SQL view shows the corresponding SQL statement.
SELECT Employees.Emp_id, Employees.[Last name], Count(Invoices.Inv_id) AS No_of_invs |
If you want to filter rows, you use the clause WHERE. There is also a similar
clause but it is used to filter groups. This is the clause HAVING.
GROUP BY column, .... |
The clause HAVING filters groups and not rows.
It can contain columns
listed by the clause GROUP BY as well as the calls to aggregate functions on columns
not listed by the clause GROUP BY. If in the previous example we asked to display
only these employees who had signed at least three invoices, we would add appropriate
content of the clause HAVING
SELECT Employees.Emp_id, Employees.[Last name], Count(Invoices.Inv_id) AS No_of_invs |
UNION, repeat steps 2-7
for all its arguments.
FROM. Apply operators
INNER JOIN, LEFT JOIN and RIGHT JOIN.
Consider all tuples of resulting rows.
WHERE to all these tuples. Retain only those that
yield True for this condition. Drop all the others, i.e. those that
yield False or Null.
GROUP BY.
HAVING to all these groups. Retain only those that
yield True for this condition. Drop all the other, i.e. those that
yield False or Null.
SELECT.
DISTINCT or DISTINCTROW after SELECT,
remove duplicates from the resulting rows.
UNION, if it is present.
ORDER BY (i.e. sort resulting rows), if it is present.
The above rules should be treated only as the operational semantics of the SQL queries.
Database systems evaluate queries in a more efficient way. For example, they never calculate
all tuples of the rows from the base tables listed by the clause FROM.
In the sequel subject "Database systems" the evaluation of queries will be further
elaborated upon.
It is sometimes convenient to create a query which depends on some parameters, e.g. the name of a person or a company. Here is the method to create such queries in the query grid.
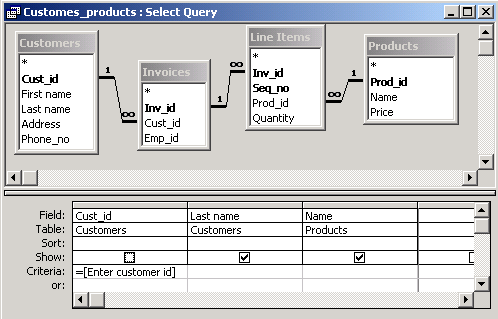
This query is equivalent to the following SQL statement.
SELECT DISTINCTROW Customers.[Last name], Products.Name |
when the system starts to evaluate this query, it displays a window where the user enters the value of the parameter.
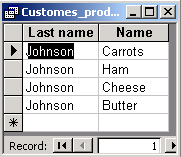
As a result we get the list of products bought by the customer identified by 7.
You might have noticed we have not discussed an important feature which is present in programming languages, i.e. the composition of statements. It is natural to compose statements in the structured approach to solving problems. If we use this method, we divide the problem into subproblems, we solve the subproblems and then we compose these solution appropriately to obtain the solution to the main problem. SQL means Structured Query Language. Thus it provides for this method of solving problems. Let us consider a problem with a subproblem which is easy to identify.
| Display the product with the highest price. |
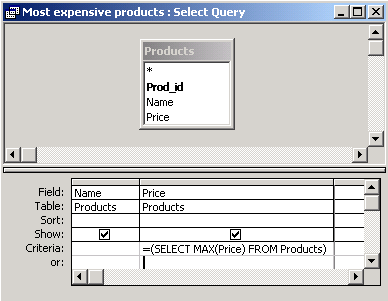
Here, the subproblem is to find the highest price. It can be solved by the following query.
SELECT MAX(Price) |
This query computes the highest value in column Price in table Products. We will use it to solve the main problem.
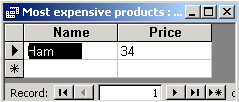
As the result we get the following.
If we switch to the SQL view, we will see the following statement.
SELECT Products.Name, Products.Price |
The condition Products.Price=(SELECT MAX(Price) FROM Products) states
that we are interested in products which have price equal to the price of the most
expensive product.
Here is another task for you.
| Display the product with the biggest quantity on a single invoice. |
So far in subqueries we have not used the columns from the superquery. Such subqueries are called uncorrelated. The result of such a subquery does not depend on the rows from the superquery.
A subquery is correlated, if its result depends on the values of columns of the rows of the superquery.
Let us consider the following query.
| For every invoice display the name of the most expensive product on this invoice. |
We want to obtain the following result.
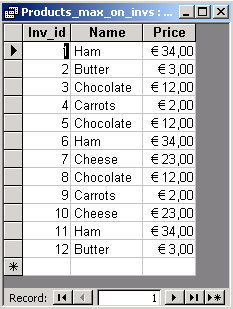
First, we solve this problem but for a while we assume that we are able to
solve the subproblem, i.e. we can find the price of the most expensive product
on the invoice identified by Invoices.Inv_id.
This red phrase
occurs in the superquery and the it is used in the subquery. Therefore it
correlates the subquery and the superquery.
SELECT |
Then we solve the subproblem.
SELECT MAX(Price) |
After we compose these two solutions, we will have the complete solution to the main problem.
SELECT |
The subquery of this query is correlated, because a column from the superquery
(Invoices.Inv_id) is used in the subquery
and influences its result.
Here is another task for you.
| Display the invoice with the highest total value. |
In MS Access a subquery may occur only on the right-hand side of a binary operator (the latest SQL standard no longer places this limitation) and must return a single value, unless it is one of the following:
IN or NOT IN
EXISTS or NOT EXISTS
Here is an example of a query with the operator IN that is used to
find employees who signed at least one invoice.
SELECT Employees.[First name], Employees.[Last name] |
It seems that by means of NOT IN
we can analogously find the employees who signed no invoices.
SELECT Employees.[First name], Employees.[Last name] |
To our surprise, this query displays no rows in spite of the fact that we have a number of such employees in the database.
This is caused by the presence of NULL values. We cannot tell that
a value is different from NULL. Some invoices are signed by no employees.
For such invoices the column Invoices.Emp_id contains
the value NULL.
The operator EXISTS allows checking whether a subquery yields the empty result
or not. For example the following condition checks if at least one employee works as
a manager.
EXISTS (SELECT "x" FROM Employees WHERE Job = "Manager")
|
The truth of this condition does not depend on the content of the clause SELECT.
We suggest using a value that is easiest to compute, e.g. "x".
The first example uses EXISTS.
| Find employees who signed at least one invoice. |
Here is the solution.
SELECT Employees.[First name], Employees.[Last name] |
Now return to the problem we did not solve before by means of the operator
NOT IN.
| Find employees who signed no invoices. |
Here is the solution which uses the operator NOT EXISTS.
SELECT Employees.[First name], Employees.[Last name] |
This time the result is correct.
At the end of the lecture let us consider the following problem.
| Select customers who are also employees of the company. |
The SQL standard defines an operator (INTERSECT)
which can be used here.
It is the intersection of relations. If MS Access provided that operator,
We would intersect two queries to tables Customers and Employees
respectively. MS Access does not have this implemented,
instead you can use a subquery and the operator NOT EXISTS.
SELECT [First name], [Last name] |
This query returns no rows from our sample database. There are no customers who are also employees. Of course, you can question the test on a person's identity based on the first and last names. However, our sample database contains no precise information on a person's identity like the SSN.
The SQL standard defines also another set operation, the difference (EXCEPT).
MS Access does not implement it as well. Instead of it, you can use
a subquery and the operator NOT EXISTS. with this hint you can easily write
the following query.
| Select customers that are not employed by the company. |
Lecture 9 was devoted to SQL, i.e. the standard language which allows accessing and updating data stored in relational (or object-relational) databases. It is widely accepted and implemented by all vendors of database systems.
We presented the following statements:
the addition of a new row into a table (INSERT),
the deletion of a row from a table (DELETE),
the update of a row of a table (UPDATE) and
the retrieval of data from a number of tables (SELECT).
A query to a database (the SELECT statement) may contain several parts
called clauses.
Clause SELECT defines the values which are to be retrieved from the database.
Clause FROM indicates the base tables to calculate these values from.
Clause WHERE states the condition which must be satisfied by these values.
Clause GROUP BY sets the partition of these values
into groups which must
be performed before returning the result of the query.
Clause HAVING states the condition which must be satisfied by these groups.
Clause ORDER BY describes how to sort the returned rows.
There are also two additional operators which can be used while building the queries.
They are the possibility to nest a subquery into a superquery and
the set union (UNION) which combines the results of two queries.
During the sequel lecture Database systems SQL will be presented in more detail.
SELECT statements.
It is used to partition the rows into groups.
INNER JOIN,
LEFT JOIN and
RIGHT JOIN.
IS [NOT] NULL,
[NOT] BETWEEN,
[NOT],
LIKE,
[NOT] IN,
[NOT] EXISTS,
UNION,
DISTINCT and
DISTINCTROW.
Build SQL statements for the following queries. Assume the above schema.